

{kind=link}
As organizations more and more undertake Apache Iceberg tables for his or her information lake architectures on Amazon Net Companies (AWS), sustaining these tables turns into essential for long-term success. With out correct upkeep, Iceberg tables can face a number of challenges: degraded question efficiency, pointless retention of previous information that ought to be eliminated, and a decline in storage price effectivity. These points can considerably influence the effectiveness and economics of your information lake. Common desk upkeep operations assist guarantee your Iceberg tables stay excessive performing, compliant with information retention insurance policies, and cost-effective for manufacturing workloads. That will help you handle your Iceberg tables at scale, AWS Glue automated these Iceberg desk upkeep operations: compaction with kind and z-order and snapshots expiration and orphan information administration. After the launch of the characteristic, many shoppers have enabled automated desk optimization via AWS Glue Information Catalog to scale back operational burden.
The Amazon SageMaker lakehouse structure now automates optimization of Iceberg tables saved in Amazon S3 with catalog-level configuration, optimizing storage in your Iceberg tables and enhancing question efficiency. Beforehand, optimizing Iceberg tables in AWS Glue Information Catalog required updating configurations for every desk individually. Now, you’ll be able to allow computerized optimization for brand spanking new Iceberg tables with one-time Information Catalog configuration. As soon as enabled, for any new desk or up to date desk, Information Catalog constantly optimizes tables by compacting small information, eradicating snapshots, and unreferenced information which might be not wanted.
This put up demonstrates an end-to-end stream to allow catalog stage desk optimization setting.
Stipulations
The next conditions are required to make use of the brand new catalog-level desk optimizations:
Allow desk optimizations on the catalog stage
The information lake administrator can allow the catalog-level desk optimization on the AWS Lake Formation console. Full the next steps:
- On the AWS Lake Formation console, select Catalogs within the navigation pane.
- Choose the catalog to be enabled with catalog-level desk optimizations.
- Select Desk optimizations tab, and select Edit in Desk optimizations, as proven within the following screenshot.
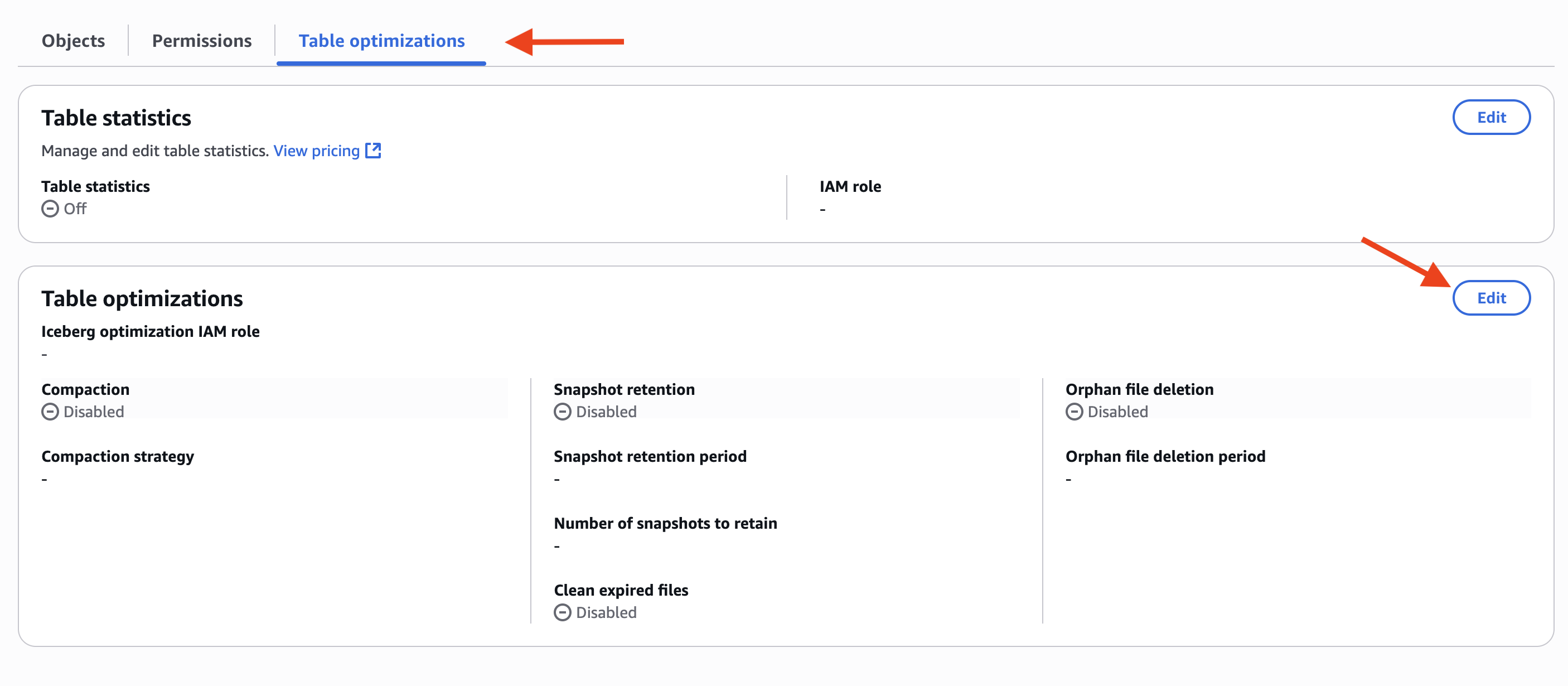
- In Optimization choices, choose Compaction, Snapshot retention, and Orphan file deletion, as proven within the following screenshot.
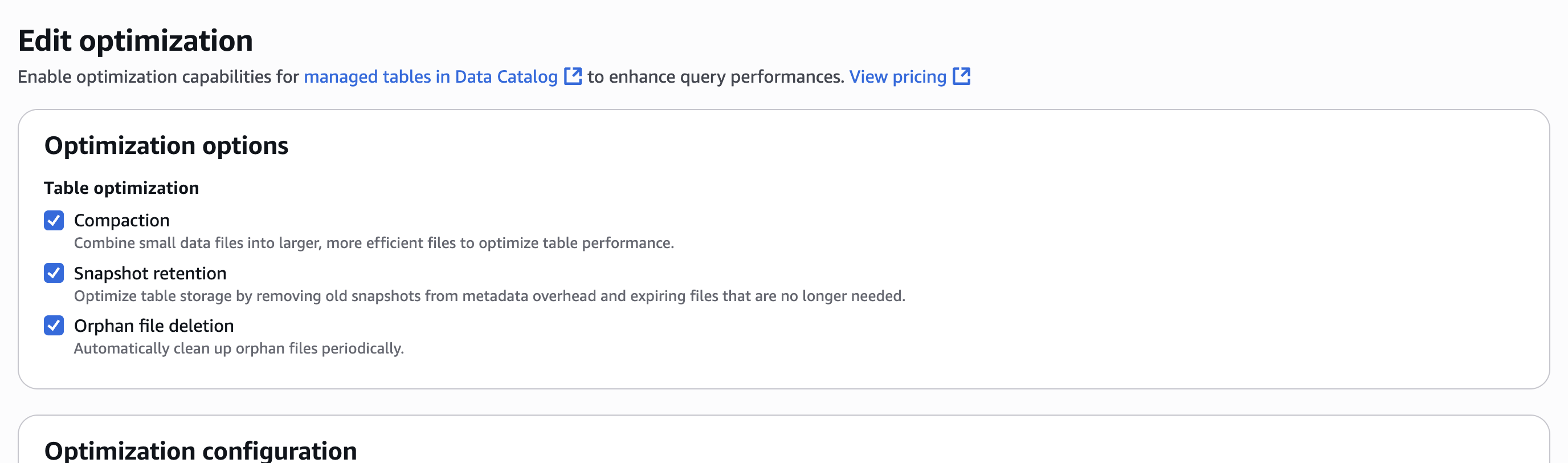
- Choose an IAM function. Seek advice from Desk optimization conditions for permissions.
- Select Grant required permissions.
- Select I acknowledge that expired information can be deleted as a part of the optimizers.
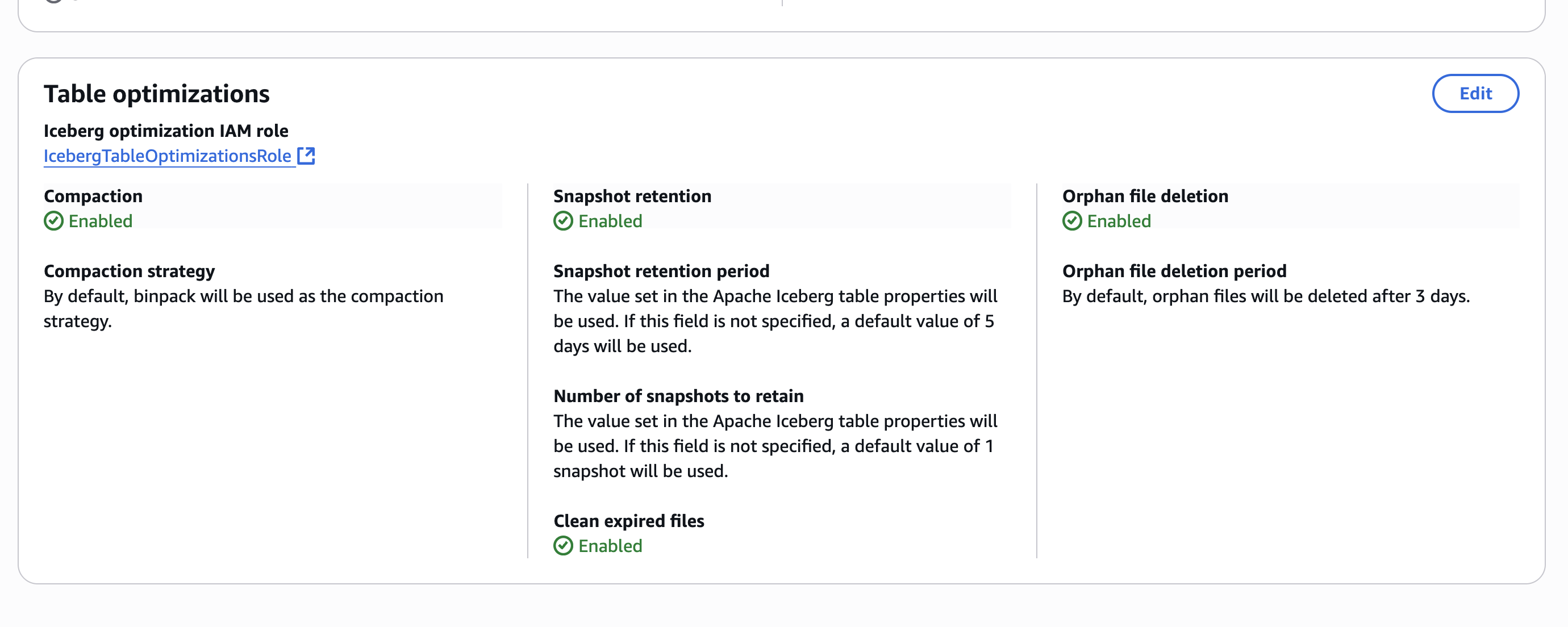
After you allow the desk optimizations on the catalog stage, the configuration is displayed on the AWS Lake Formation console, as proven within the following screenshot.
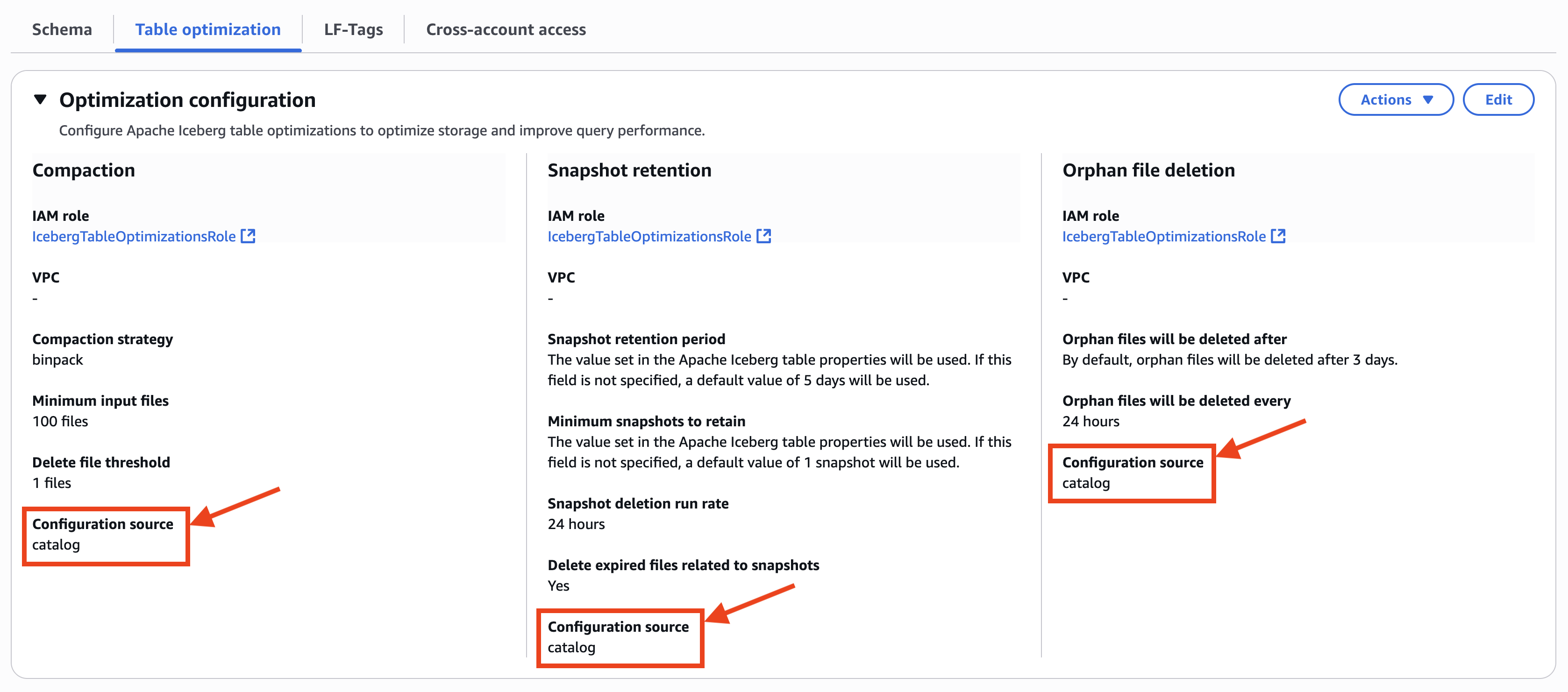
When you choose an Iceberg desk registered within the catalog, you’ll be able to verify that the desk optimizations configuration is inherited from the desk view as a result of Configuration supply reveals catalog, as proven within the following screenshot.
The desk optimizations historical past is displayed on the desk view. The next consequence reveals one of many compaction runs by the desk optimizations.
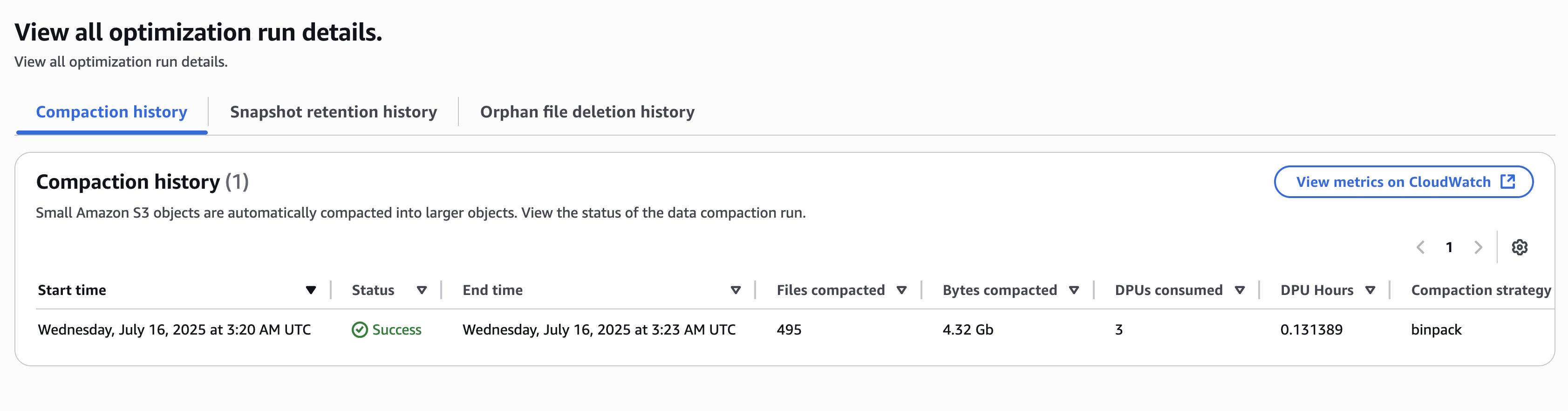
The catalog-level desk optimizations for all databases and Iceberg tables at the moment are enabled.
Customise setting of desk optimizations at each the catalog and table-level
Though the catalog-level optimization applies frequent settings throughout all databases and Iceberg tables in your catalog, you may wish to apply completely different methods for particular Iceberg tables. You should utilize AWS Glue Information Catalog to allow each catalog-level and table-level optimizations primarily based on particular desk traits and entry patterns. For instance, along with configuring the catalog-level compaction with the bin-pack technique for general-purpose Iceberg tables, you’ll be able to apply the type technique on the table-level to tables with frequent vary queries on timestamp columns.
This part reveals configuring catalog-level and table-specific optimizations via a sensible state of affairs. Think about a real-time analytics desk with frequent write operations that generates extra orphan information on account of fixed metadata updates. Customers additionally run selective queries filtering particular columns, which makes sort-order technique preferable. Full the next steps:
- Choose one other Iceberg desk in the identical catalog as earlier than to configure the table-level optimizations on the AWS Lake Formation console. At this level, the catalog-level desk optimizations are configured for this desk.
- Select Edit in Optimization configuration, as proven within the following screenshot.
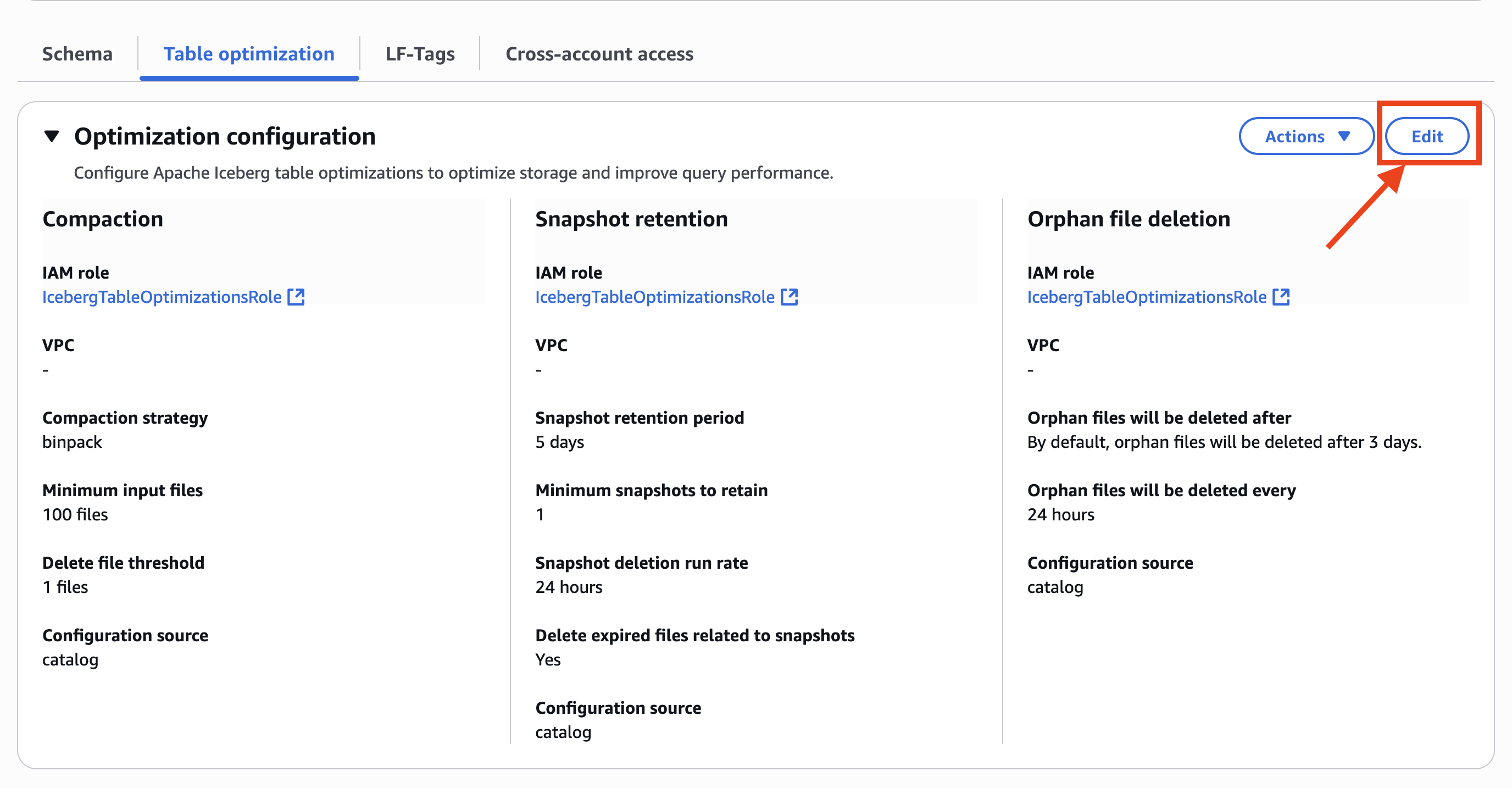
- In Optimization choices, select Compaction, Snapshot retention, and Orphan file deletion.
- In Optimization configuration, select Customise settings.
- Choose the identical IAM function.
- In Compaction configuration, choose Kind, as proven within the following screenshot. Additionally configure 80 information to Minimal enter information, which is a threshold of the variety of information to set off the compaction. To configure Kind, a form order must be outlined in your Iceberg desk. You possibly can outline the type order with Spark SQL reminiscent of
ALTER TABLE db.tbl WRITE ORDERED BY <columns>.
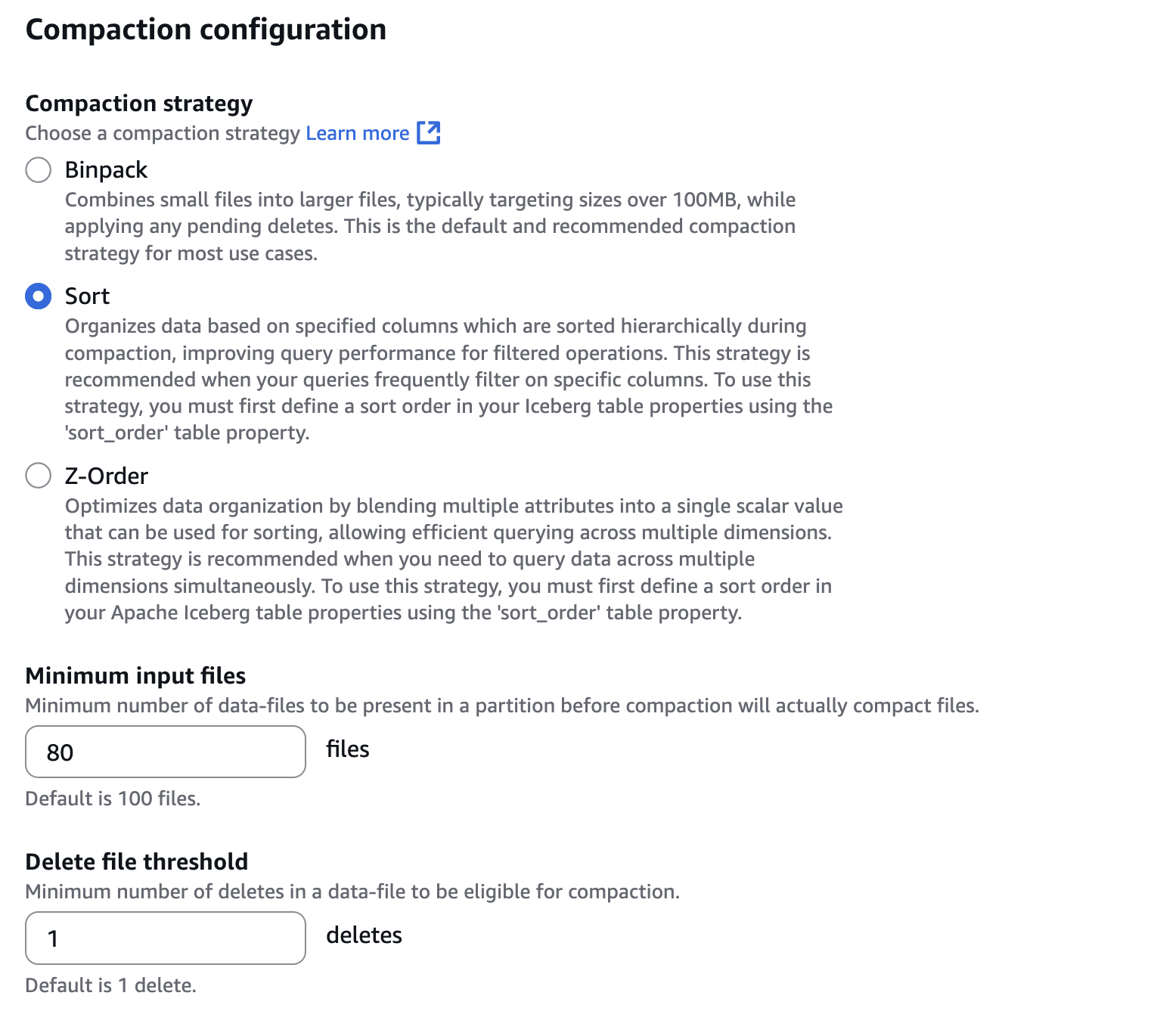
- In Snapshot retention configuration and Snapshot deletion run charge, choose Specify a customized worth in hours. Then, configure 12 hours to the interval between two deletion job runs, as proven within the following screenshot.

- In Orphan file deletion configuration, configure 1 day to Recordsdata underneath the supplied Desk Location with a creation time older than this variety of days can be deleted if they’re not referenced by the Apache Iceberg Desk metadata.

- Select Grant required permissions.
- Select I acknowledge that expired information can be deleted as a part of the optimizers.
- Select Save.
- The Desk optimization tab on the AWS Lake Formation console shows the customized setting of desk optimizers. In Compaction, Compaction technique is configured to kind and Minimal enter information can also be configured to 80 information. In Snapshot retention, Snapshot deletion run charge is configured to 12 hours. In Orphan file deletion, Orphan information can be deleted after is configured to 1 days, as proven within the following screenshot.
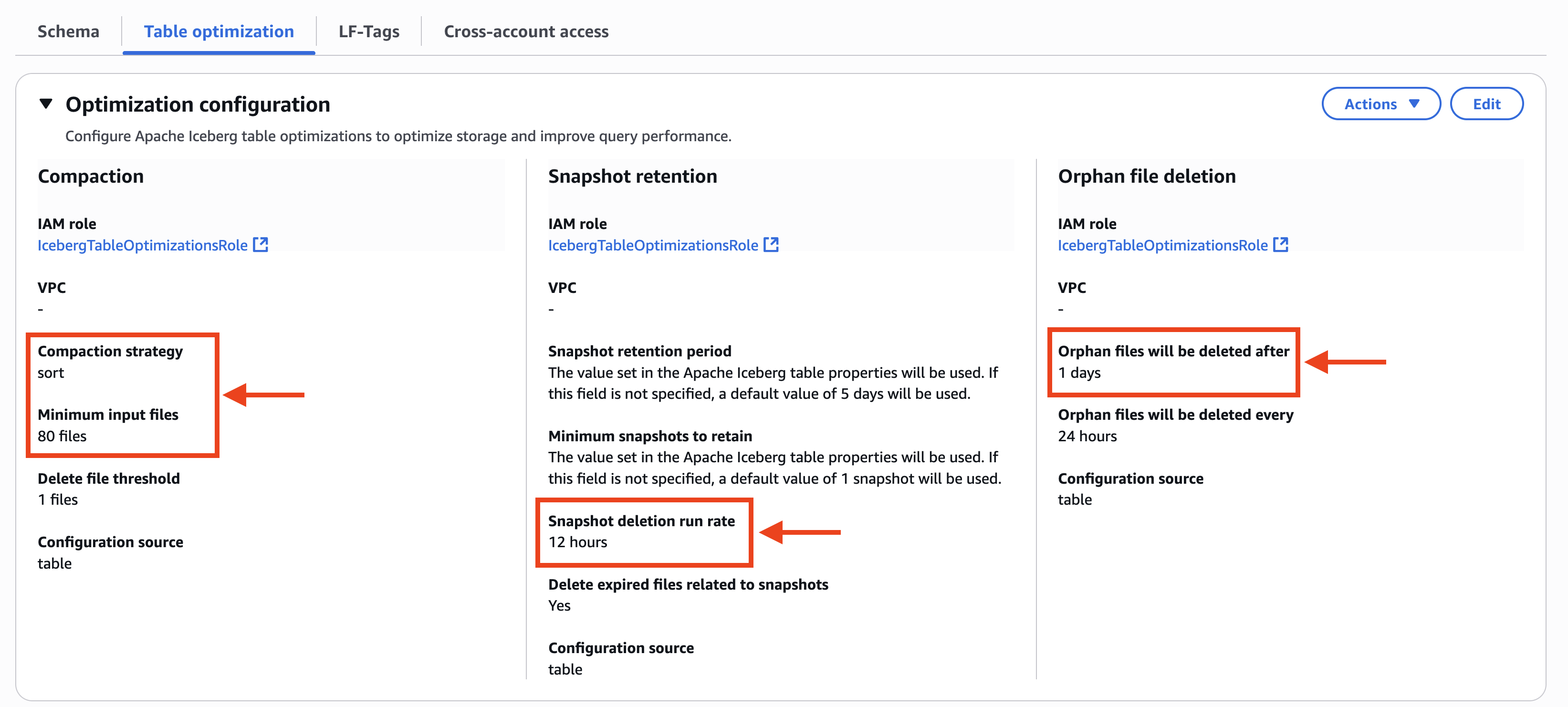
The compaction historical past reveals kind as its table-level compaction technique even when the technique within the catalog-level is configured to binpack, as proven within the following screenshot.
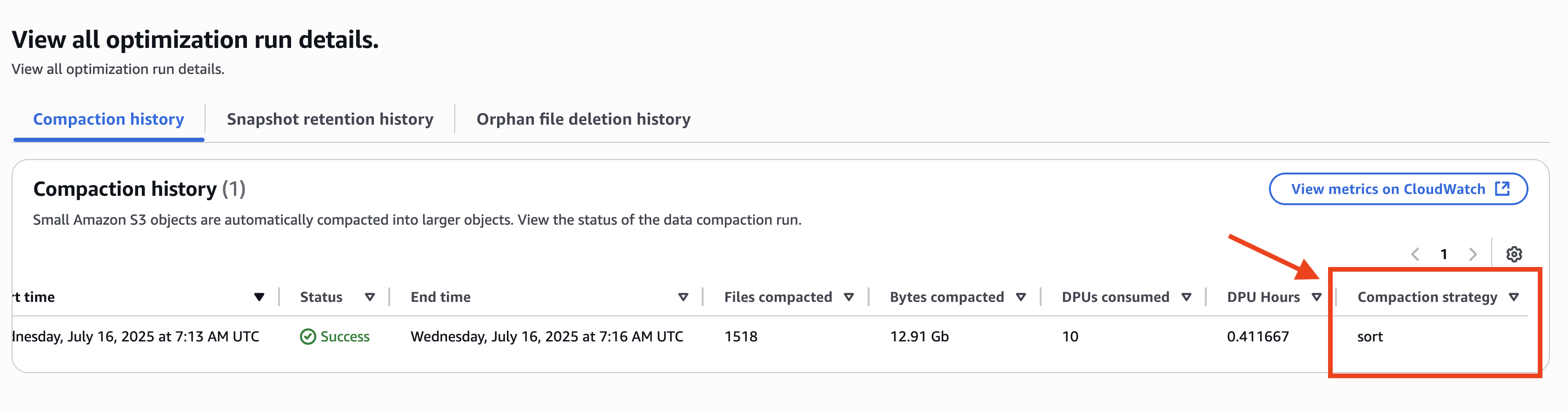
On this state of affairs, the table-specific optimizations are configured together with the catalog-level optimizations. Combining the desk and catalog-level optimizations means you’ll be able to extra flexibly handle your Iceberg desk information deletions and compactions.
Conclusion
On this put up, we demonstrated easy methods to allow and handle utilizing Amazon SageMaker lakehouse structure with AWS Glue Information Catalog’s catalog-level desk optimization characteristic for Iceberg tables. This enhancement considerably simplifies the administration of Iceberg tables as a result of you’ll be able to allow automated upkeep operations throughout all tables with a single setting. As an alternative of configuring optimization settings for particular person tables, now you can preserve your whole information lake extra effectively, lowering operational overhead whereas making certain constant optimization insurance policies. We suggest enabling catalog-level desk optimization that can assist you preserve a well-organized, high-performing, and cost-effective information lake whereas releasing up your groups to concentrate on deriving worth out of your information.
Check out this characteristic to your personal use case and share your suggestions and questions within the feedback. To be taught extra about AWS Glue Information Catalog desk optimizer, go to Optimizing Iceberg tables.
Acknowledgment: A particular because of everybody who contributed to the event and launch of catalog stage optimization: Siddharth Padmanabhan Ramanarayanan, Dhrithi Chidananda, Noella Jiang, Sangeet Lohariwala, Shyam Rathi, Anuj Jigneshkumar Vakil, and Jeremy Music.
Concerning the authors
 Tomohiro Tanaka is a Senior Cloud Assist Engineer at Amazon Net Companies (AWS). He’s enthusiastic about serving to clients use Apache Iceberg for his or her information lakes on AWS. In his free time, he enjoys a espresso break along with his colleagues and making espresso at residence.
Tomohiro Tanaka is a Senior Cloud Assist Engineer at Amazon Net Companies (AWS). He’s enthusiastic about serving to clients use Apache Iceberg for his or her information lakes on AWS. In his free time, he enjoys a espresso break along with his colleagues and making espresso at residence.
 Noritaka Sekiyama is a Principal Massive Information Architect with AWS Analytics providers. He’s liable for constructing software program artifacts to assist clients. In his spare time, he enjoys biking on his highway bike.
Noritaka Sekiyama is a Principal Massive Information Architect with AWS Analytics providers. He’s liable for constructing software program artifacts to assist clients. In his spare time, he enjoys biking on his highway bike.
 Sandeep Adwankar is a Senior Product Supervisor at Amazon Net Companies (AWS). Primarily based within the California Bay Space, he works with clients across the globe to translate enterprise and technical necessities into merchandise clients can use to enhance how they handle, safe, and entry information.
Sandeep Adwankar is a Senior Product Supervisor at Amazon Net Companies (AWS). Primarily based within the California Bay Space, he works with clients across the globe to translate enterprise and technical necessities into merchandise clients can use to enhance how they handle, safe, and entry information.
 Siddharth Padmanabhan Ramanarayanan is a Senior Software program Engineer on the AWS Glue and AWS Lake Formation group, the place he focuses on constructing scalable distributed methods for information analytics workloads. He’s enthusiastic about serving to clients optimize their cloud infrastructure for efficiency and value effectivity.
Siddharth Padmanabhan Ramanarayanan is a Senior Software program Engineer on the AWS Glue and AWS Lake Formation group, the place he focuses on constructing scalable distributed methods for information analytics workloads. He’s enthusiastic about serving to clients optimize their cloud infrastructure for efficiency and value effectivity.