

{kind=link}
Buyer help calls maintain a wealth of data, however discovering the time to manually comb by way of these recordings for insights isn’t straightforward. Think about in case you might immediately flip these lengthy recordings into clear summaries, observe how the sentiment shifts all through the decision, and even get tailor-made insights primarily based on the way you need to analyze the dialog. Sounds helpful?
On this article, we’ll stroll by way of making a sensible software I constructed SnapSynapse (click on right here), to do precisely that! Utilizing instruments like pyannote.audio for speaker diarization(identification), Whisper for transcription, and Gemini-1.5 Professional for producing AI-driven summaries, I’ll present how one can automate the method of turning help name recordings into actionable insights. Alongside the way in which, you’ll see clear and refine transcriptions, generate customized summaries primarily based on consumer enter, and observe sentiment traits—all with easy-to-follow code snippets. This can be a hands-on information to constructing a software that goes past transcription that can assist you perceive and enhance your buyer help expertise.
Studying Targets
- Perceive use pyannote.audio for speaker diarization, separating totally different voices in buyer help recordings.
- Be taught to generate correct transcriptions from audio recordsdata utilizing Whisper and clear them by eradicating filler phrases and irrelevant textual content.
- Uncover create tailor-made summaries utilizing Gemini-1.5 Professional, with customizable prompts to suit totally different evaluation wants.
- Discover strategies for performing sentiment evaluation on conversations and visualizing sentiment traits all through a name.
- Acquire hands-on expertise in constructing an automatic pipeline that processes audio knowledge into structured insights, making it simpler to research and enhance buyer help interactions.
This text was printed as part of the Knowledge Science Blogathon.
What’s SnapSynapse?
SnapSynapse is a helpful software for turning buyer help calls into useful insights. It breaks down conversations by speaker, transcribes every little thing, and highlights the general temper and key factors, so groups can shortly perceive what prospects want. Utilizing fashions like Pyannote for diarization, Whisper for transcription, and Gemini for summaries, SnapSynapse delivers clear summaries and sentiment traits with none trouble. It’s designed to assist help groups join higher with prospects and enhance service, one dialog at a time.
Key Options
Beneath are the necessary key options of SnapSynapse:
- Speaker diarization/identification
- Dialog transcript technology
- Time Stamps technology dialogue sensible
- Use case primarily based Abstract technology
- Sentiment Evaluation scores
- Sentiment Evaluation by way of visualization
Constructing SnapSynapse: Core Options and Performance
On this part, we’ll discover the core options that make SnapSynapse a robust software for buyer help evaluation. From mechanically diarizing and transcribing calls to producing dynamic dialog summaries, these options are constructed to reinforce help staff effectivity. With its skill to detect sentiment traits and supply actionable insights, SnapSynapse simplifies the method of understanding buyer interactions.
In case, if you wish to take a look at the entire supply code, discuss with the recordsdata within the repo : repo_link
We’ll want OPEN AI API and GEMINI API to run this challenge. You may get the API’s right here – Gemini API , OpenAI API
Venture movement:
speaker diarization -> transcription -> time stamps -> cleansing -> summarization -> sentiment evaluation
Step1: Speaker Diarization and Transcription Technology
In step one, we’ll use a single script to take an audio file, separate the audio system (diarization), generate a transcription, and assign timestamps. Right here’s how the script works, together with a breakdown of the code and key features:
Overview of the Script
This Python script performs three foremost duties in a single go:
- Speaker Diarization: Identifies totally different audio system in an audio file and separates their dialogue.
- Transcription: Converts every speaker’s separated audio segments into textual content.
- Timestamping: Provides timestamps for every spoken phase.
Imports and Setup
- We begin by importing needed libraries like pyannote.audio for speaker diarization, openai for transcription, and pydub to deal with audio segments.
- Atmosphere variables are loaded utilizing dotenv, so we are able to securely retailer our OpenAI API key.
Principal Perform: Diarization + Transcription with Timestamps
The core perform, transcribe_with_diarization(), combines all of the steps:
- Diarization: Calls perform_diarization() to get speaker segments.
- Section Extraction: Makes use of pydub to chop the audio file into chunks primarily based on every phase’s begin and finish instances.
- Transcription: For every chunk, it calls the Whisper mannequin by way of OpenAI’s API to get textual content transcriptions.
- Timestamp and Speaker Data: Every transcription is saved with its corresponding begin time, finish time, and speaker label.
def transcribe_with_diarization(file_path):
diarization_result = perform_diarization(file_path)
audio = AudioSegment.from_file(file_path)
transcriptions = []
for phase, _, speaker in diarization_result.itertracks(yield_label=True):
start_time_ms = int(phase.begin * 1000)
end_time_ms = int(phase.finish * 1000)
chunk = audio[start_time_ms:end_time_ms]
chunk_filename = f"{speaker}_segment_{int(phase.begin)}.wav"
chunk.export(chunk_filename, format="wav")
with open(chunk_filename, "rb") as audio_file:
transcription = shopper.audio.transcriptions.create(
mannequin="whisper-1",
file=audio_file,
response_format="json"
)
transcriptions.append({
"speaker": speaker,
"start_time": phase.begin,
"end_time": phase.finish,
"transcription": transcription.textual content
})
print(f"Transcription for {chunk_filename} by {speaker} accomplished.")
Saving the Output
- The ultimate transcriptions, together with speaker labels and timestamps, are saved to diarized_transcriptions.json, making a structured file of the dialog.
- Lastly, we run the perform on a check audio file, test_audio_1.wav, to see the complete diarization and transcription course of in motion.
A Glimpse of the output generated and obtained saved in diarized_transcription.py file:
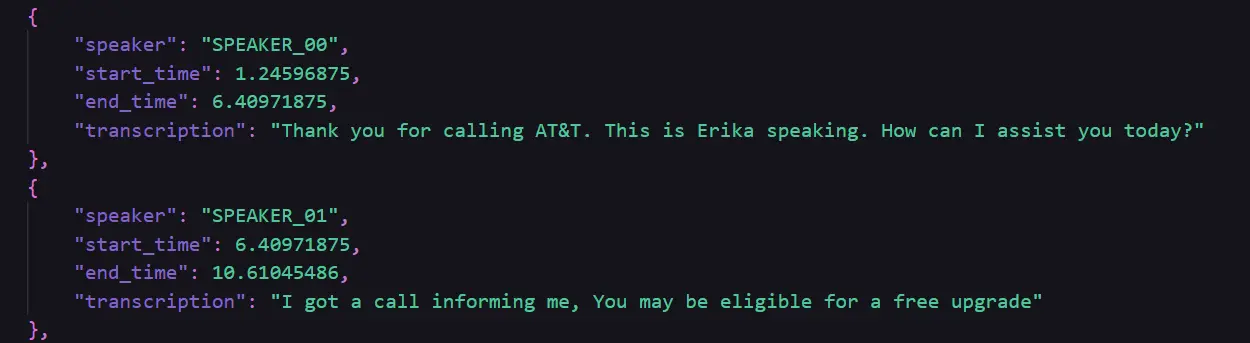
Step2: Cleansing of the Generated Transcription
- This file focuses on cleansing the transcriptions generated from the diarization and transcription course of.
- It masses the diarized transcriptions from a JSON file and removes frequent filler phrases like “um,” “uh,” and “you already know” to enhance readability.
- Moreover, it eliminates additional white areas and normalizes the textual content to make the transcription extra concise and polished.
- After cleansing, the system saves the brand new transcriptions in a JSON file named cleaned_transcription.py, guaranteeing that the information is prepared for additional evaluation or perception technology.
# perform to scrub the transcription textual content
def clean_transcription(textual content):
# Listing of frequent filler phrases
filler_words = [
"um", "uh", "like", "you know", "actually", "basically", "I mean",
"sort of", "kind of", "right", "okay", "so", "well", "just"
]
# regex sample to match filler phrases (case insensitive)
filler_pattern = re.compile(r'b(' + '|'.be a part of(filler_words) + r')b', re.IGNORECASE)
# Take away filler phrases
cleaned_text = filler_pattern.sub('', textual content)
# Take away additional whitespace
cleaned_text = re.sub(r's+', ' ', cleaned_text).strip()
return cleaned_textStep3: Producing Abstract utilizing GEMINI 1.5 professional
Within the subsequent step, we use the Gemini API to generate structured insights and summaries primarily based on the cleaned transcriptions. We make the most of the Gemini 1.5 professional mannequin for pure language processing to research buyer help calls and supply actionable summaries.
Right here’s a breakdown of the performance:
- Mannequin Setup: The Gemini mannequin is configured utilizing the google.generativeai library, with the API key securely loaded. It helps producing insights primarily based on totally different immediate codecs.
- Prompts for Evaluation: A number of predefined prompts are designed to research varied features of the help name, reminiscent of common name summaries, speaker exchanges, complaints and resolutions, escalation wants, and technical concern troubleshooting.
- Generate Structured Content material: The perform generate_analysis() takes the cleaned transcription textual content and processes it utilizing one of many predefined prompts. It organizes the output into three sections: Abstract, Motion Gadgets, and Key phrases.
- Consumer Interplay: The script permits the consumer to select from a number of abstract codecs. The consumer’s alternative determines which immediate is used to generate the insights from the transcription.
- Output Technology: After processing the transcription, the ensuing insights—organized right into a structured JSON format—are saved to a file. This structured knowledge makes it simpler for help groups to extract significant data from the decision.
A brief glimpse of various prompts used:

A glimpse of the output generated:
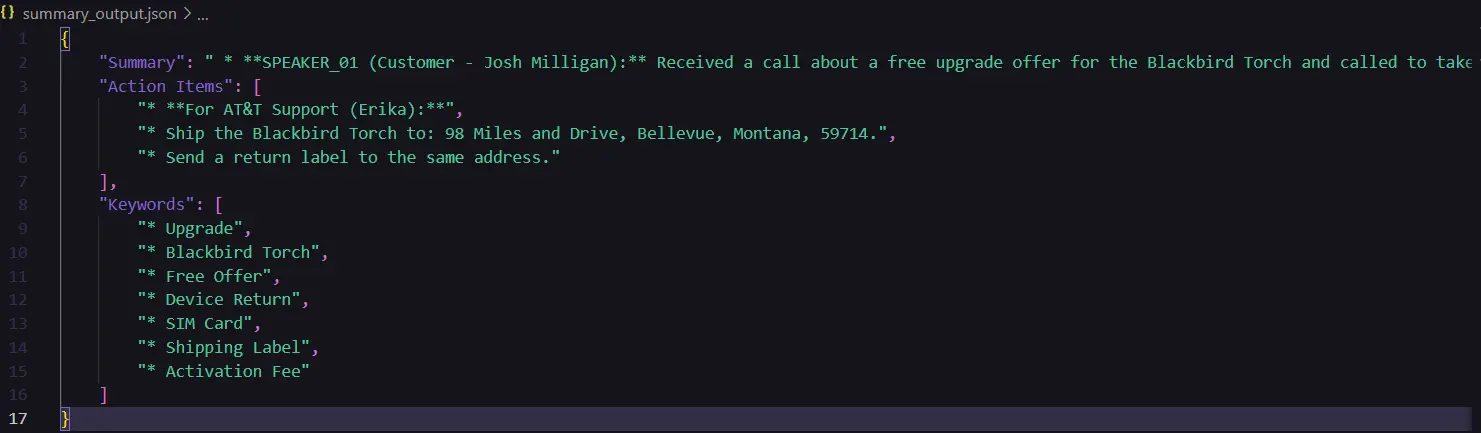
Step 4: Sentiment Evaluation
Additional, within the subsequent step we carry out sentiment evaluation on buyer help name transcriptions to evaluate the emotional tone all through the dialog. It makes use of the VADER sentiment evaluation software from NLTK to find out sentiment scores for every phase of the dialog.
Right here’s a breakdown of the method:
- Sentiment Evaluation Utilizing VADER: The script makes use of SentimentIntensityAnalyzer from the VADER (Valence Conscious Dictionary and sEntiment Reasoner) lexicon. It assigns a sentiment rating for every phase, which features a compound rating indicating the general sentiment (optimistic, impartial, or unfavorable).
- Processing Transcription: The cleaned transcription is loaded from a JSON file. Every entry within the transcription is evaluated for sentiment, and the outcomes are saved with the speaker label and corresponding sentiment scores. The script calculates the entire sentiment rating, the typical sentiment for the shopper and help agent, and categorizes the general sentiment as Constructive, Impartial, or Detrimental.
- Sentiment Development Visualization: Utilizing Matplotlib, the script generates a line plot exhibiting the pattern of sentiment over time, with the x-axis representing the dialog segments and the y-axis exhibiting the sentiment rating.
- Output: The system saves the sentiment evaluation outcomes, together with the scores and total sentiment, to a JSON file for straightforward entry and evaluation later. It visualizes the sentiment pattern in a plot to supply an summary of the emotional dynamics in the course of the help name.
Code used for calculating the general sentiment rating
# Calculate the general sentiment rating
overall_sentiment_score = total_compound / len(sentiment_results)
# Calculate common sentiment for Buyer and Agent
average_customer_sentiment = customer_sentiment / customer_count if customer_count else 0
average_agent_sentiment = agent_sentiment / agent_count if agent_count else 0
# Decide the general sentiment as optimistic, impartial, or unfavorable
if overall_sentiment_score > 0.05:
overall_sentiment = "Constructive"
elif overall_sentiment_score < -0.05:
overall_sentiment = "Detrimental"
else:
overall_sentiment = "Impartial"Code used for producing the plot
def plot_sentiment_trend(sentiment_results):
# Extract compound sentiment scores for plotting
compound_scores = [entry['sentiment']['compound'] for entry in sentiment_results]
# Create a single line plot exhibiting sentiment pattern
plt.determine(figsize=(12, 6))
plt.plot(compound_scores, coloration="purple", linestyle="-", marker="o", markersize=5, label="Sentiment Development")
plt.axhline(0, coloration="gray", linestyle="--") # Add a zero line for impartial sentiment
plt.title("Sentiment Development Over the Buyer Assist Dialog", fontsize=16, fontweight="daring", coloration="darkblue")
plt.xlabel("Section Index")
plt.ylabel("Compound Sentiment Rating")
plt.grid(True, linestyle="--", alpha=0.5)
plt.legend()
plt.present()Sentiment Evaluation Scores generated:

Sentiment Evaluation Plot generated:
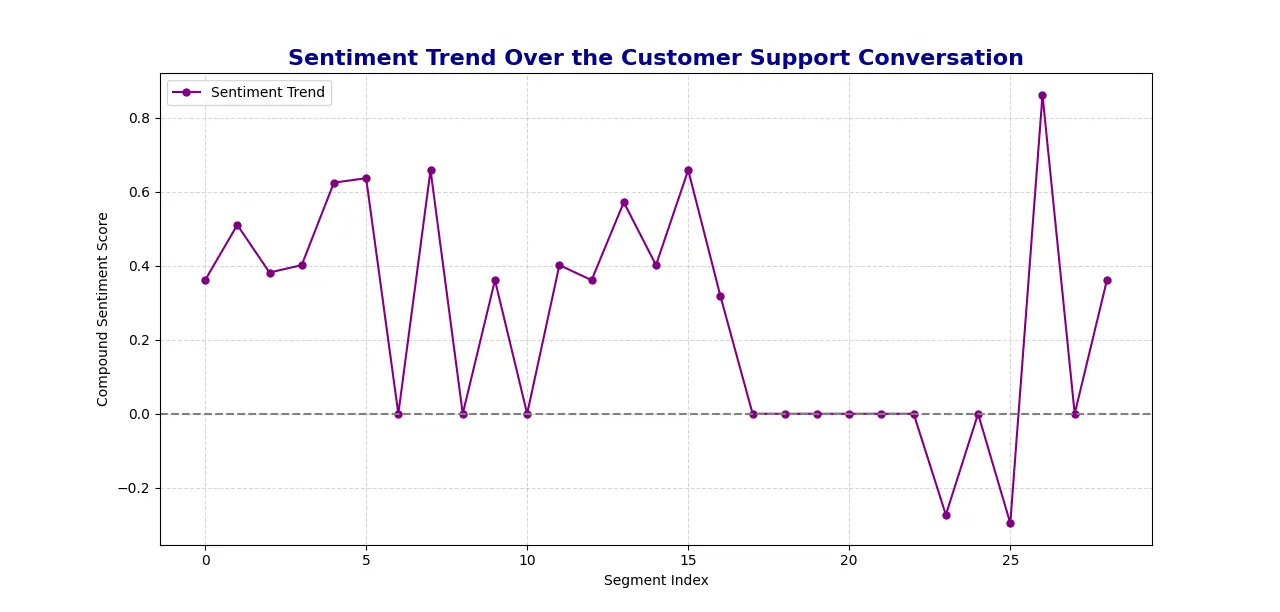
Setting Up SnapSynapse: A Step-by-Step Information
You will discover the code repository right here – repo_link
Now, let’s stroll by way of arrange and run SnapSynapse in your native machine:
Step1: Clone the Repository
Begin by cloning the challenge repository to your native machine to start utilizing SnapSynapse. This gives entry to the appliance’s supply code and all its important parts.
git clone https://github.com/Keerthanareddy95/SnapSynapse.git
cd SnapSynapseStep2: Setup the Digital Atmosphere
A digital surroundings helps isolate dependencies and ensures your challenge runs easily. This step units up an unbiased workspace for SnapSynapse to function with out interference from different packages.
# For Home windows:
python -m venv venv
# For macOS and Linux:
python3 -m venv venvStep3: Activate the Digital Atmosphere
# For Home windows:
.venvScriptsactivate
# For macOS and Linux:
supply venv/bin/activateStep4: Set up Required Dependencies
With the digital surroundings in place, the following step is to put in all needed libraries and instruments. These dependencies allow the core functionalities of SnapSynapse, together with transcript technology, speaker diarization, time stamp technology, abstract technology, sentiment evaluation scores, visualization and extra.
pip set up -r necessities.txt Step5: Arrange the Atmosphere Variables
To leverage AI-driven insights, diarization, transcription and summarization and also you’ll must configure API keys for Google Gemini and OPEN AI Whisper.
Create a .env file within the root of the challenge and add your API keys for Google Gemini and OPEN AI Whisper.
GOOGLE_API_KEY="your_google_api_key"
OPENAI_API_KEY="your_open_ai_api_key"Step6: Run the Software
- Begin by operating the transcription.py file: This file performs the transcription technology, speaker diarization and time stamp technology. And it saves the output in a json file named diarized_transcriptions.json.
- Subsequent, run the cleansing.py file: This file will take the diarized_transcriptions.py file as enter and cleans the transcription and saves the leads to cleaned_transcription.json file.
- Additional, run the abstract.py file: right here you could point out the GEMINI API key. This file will take the cleaned_transcription.py file as enter and prompts the consumer to enter the type of abstract they need to generate primarily based on their use case. Based mostly on the consumer enter, the system passes the corresponding immediate to GEMINI, which generates the abstract. The system then shops the generated abstract in a JSON file named
summary_output.json. - Lastly, run the sentiment_analysis.py file: Working this file will generate the general sentiment scores and likewise a graphical illustration of the sentiment evaluation scores and the way they progressed by way of the audio file.
Allow us to now look onto the instruments utilized in improvement for SnapSynapse under:
- pyannote.audio : Gives the Pipeline module for performing speaker diarization, which separates totally different audio system in an audio file.
- openai: Used to work together with OpenAI’s API for transcription by way of the Whisper mannequin.
- pydub (AudioSegment): Processes audio recordsdata, permitting segmentation and export of audio chunks by speaker.
- google.generativeai: A library to entry Google Gemini fashions, used right here to generate structured summaries and insights from buyer help transcriptions.
- NLTK (Pure Language Toolkit): A library for pure language processing, particularly used right here to import the SentimentIntensityAnalyzer from VADER to research sentiment within the audio file.
- Matplotlib: A visualization library typically used with plt, included right here for visualization of the sentiment all through the audio file.
Conclusion
In a nutshell, SnapSynapse revolutionizes buyer help evaluation by remodeling uncooked name recordings into actionable insights. From speaker diarization and transcription to producing a structured abstract and sentiment evaluation, SnapSynapse streamlines each step to ship a complete view of buyer interactions. With the ability of the Gemini mannequin’s tailor-made prompts and detailed sentiment monitoring, customers can simply acquire summaries and traits that spotlight key insights and help outcomes.
A giant shoutout to Google Gemini, Pyannote Audio, and Whisper for powering this challenge with their revolutionary instruments!
You possibly can take a look at the repo right here.
Key Takeaways
- SnapSynapse allows customers to course of buyer help calls end-to-end—from diarizing and transcribing to producing summaries.
- With 5 distinct immediate decisions, customers can tailor summaries to particular wants, whether or not specializing in points, motion gadgets, or technical help. This function helps learners discover immediate engineering and experiment with how totally different inputs affect AI-generated outputs.
- SnapSynapse tracks sentiment traits all through conversations, offering a visible illustration of tone shifts that assist customers higher perceive buyer satisfaction. For learners, it’s an opportunity to use NLP strategies and learn to interpret sentiment knowledge in real-world purposes.
- SnapSynapse automates transcription cleanup and evaluation, making buyer help insights simply accessible for quicker, data-driven choices. Learners profit from seeing how automation can streamline knowledge processing, permitting them to give attention to superior insights moderately than repetitive duties.
Continuously Requested Questions
A. SnapSynapse can deal with audio recordsdata of the codecs mp3 and wav.
A. SnapSynapse makes use of Whisper for transcription, adopted by a cleanup course of that removes filler phrases, pauses, and irrelevant content material.
A. Sure! SnapSynapse presents 5 distinct immediate choices, permitting you to decide on a abstract format tailor-made to your wants. These embody focus areas like motion gadgets, escalation wants, and technical points.
A. SnapSynapse’s sentiment evaluation assesses the emotional tone of the dialog, offering a sentiment rating and a pattern graph.
A. Buyer Name Evaluation makes use of AI-powered instruments to transcribe, analyze, and extract useful insights from buyer interactions, serving to companies enhance service, establish traits, and improve buyer satisfaction.
A. By buyer name evaluation, companies can acquire a deeper understanding of buyer sentiment, frequent points, and agent efficiency, resulting in extra knowledgeable choices and improved customer support methods.
The media proven on this article shouldn’t be owned by Analytics Vidhya and is used on the Creator’s discretion.
Hello, I’m Katasani Keerthana Reddy, a passionate problem-solver on the intersection of information science and synthetic intelligence. With a knack for remodeling uncooked knowledge into actionable insights, I am at present dwelling into the world of AI. My journey has taken me from growing dynamic AIOps programs at ThoughtData to crafting insightful knowledge instruments like InsightMate and main AI/ML initiatives as a Google DSC Lead. Once I’m not diving into knowledge, you’ll discover me championing revolutionary initiatives or connecting with fellow tech fanatics. Let’s flip knowledge challenges into alternatives!